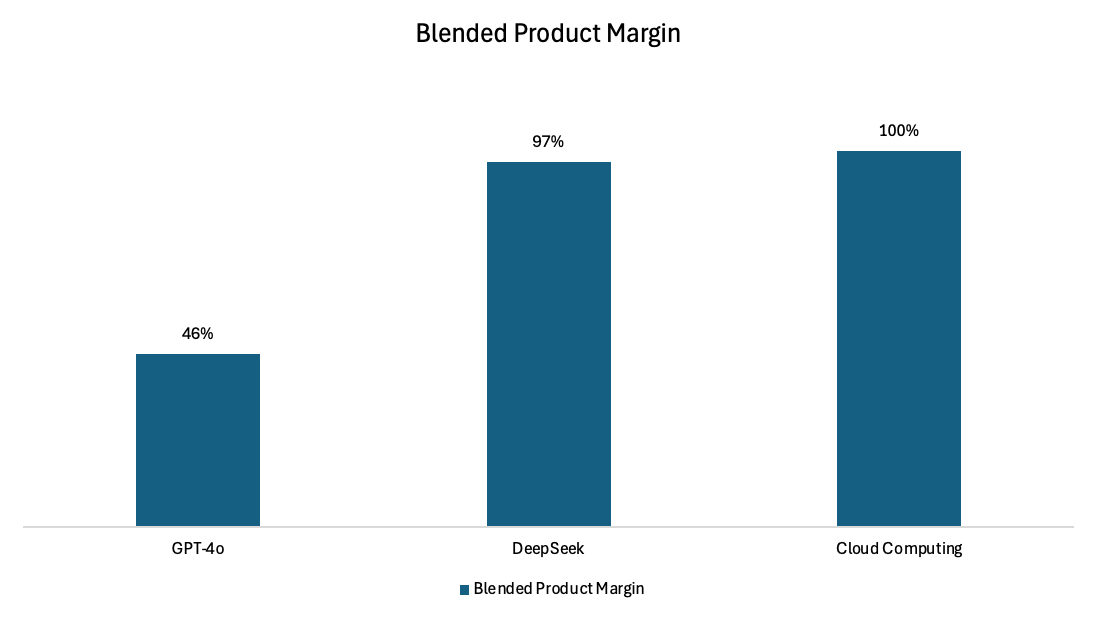The recent emergence of DeepSeek, a Chinese AI startup achieving breakthrough performance at a fraction of established models' costs, sent shockwaves through global markets, erasing $1 trillion in market value overnight. This market reaction reflects more than typical tech sector volatility — it signals a fundamental shift in how we value AI companies and capabilities.
While it is prudent to view the current AI frenzy as a classic bubble, complete with well-founded exuberance yet unsustainable valuations, this essay argues that we're witnessing something more nuanced: a necessary phase of creative destruction that will reshape the economics of intelligence itself.
Thanks for reading Compounding Thoughts! Subscribe for free to receive new posts and support my work.
This analysis explores the AI bubble's transformative potential through several key lenses.
First, we examine how bubbles historically drive technological innovation, drawing on Byrne Hobart's insights about their role in infrastructure development. Next, we analyze the distinct "capital metabolism" of the AI market — how it processes investment and drives technical breakthroughs. Through a detailed case study of LegalZoom's unit economics, we examine why it is inevitable that AI companies will achieve the kind of cost efficiency that made traditional software businesses so lucrative.
The essay's latter half focuses on the future, examining how DeepSeek's breakthrough suggests a path toward a new economic reality for on-demand intelligence. We explore two competing visions: one where AI remains inherently expensive, ending the era of high-margin software businesses, and another where AI follows cloud computing's path toward near-zero marginal costs.
Finally, we consider how this transformation will reshape business models, user interfaces, and market structure — investigating the implications of the transition from deterministic software to probabilistic AI and how that fundamentally changes how computers can serve human needs.
I. The Productive Nature of Bubbles
When I published my first analysis on AI nearly two years ago, the landscape looked vastly different. OpenAI had just launched GPT-4, Midjourney was the most impressive model available, and very few AI software applications had achieved product-market fit.
Since then, we've witnessed an unprecedented convergence of financial, human, and social capital around AI. The U.S. government's Project Stargate, a $500B public-private AI consortium, exemplifies this massive resource mobilization. Some additional evidence:
AI startups captured 46.4% of the total $209 billion raised in U.S. venture capital funding in 2024 (Reuters).
Overall VC investment increased 57% from Q3 2024 to Q4 2024, rising from $39.6 billion to $62.2 billion (EY).
AI startup investments in 2024 were up over 80% compared to the previous year (Barron’s).
While this might appear as classic bubble behavior, Byrne Hobart's analysis in new book Boom: Bubbles and the End of Stagnation, offers a more nuanced perspective. Bubbles, he argues, serve as essential catalysts for innovation by creating concentrated periods of intensive development. They work because humans are inherently social creatures who construct reality through collective behavior. When a technology demonstrates enough potential to attract massive capital and talent, it creates powerful FOMO (fear of missing out) effects that reshape risk tolerance and investment patterns.
This is how economic history unfolds. The railroad boom of the 19th century and the dot-com bubble followed a similar pattern. The bubble inflates, capital floods in, industries transform, excesses get corrected, and the surviving innovations reshape the world.
Hobart puts it succinctly:
Bubbles create clusters in time rather than space... If you know others are building infrastructure your product needs, it becomes less risky to build. Amazon benefited from AOL's internet promotion, AOL gained from Yahoo's content, and the cycle continued.
This virtuous cycle of infrastructure development, while eventually exceeding immediate demand, leaves behind crucial technological foundations that enable future innovation.
The DeepSeek phenomenon illustrates this dynamic perfectly. Their R1 model rivals OpenAI's capabilities at a fraction of the cost and computing requirements. While this triggered a massive market selloff, it actually validates the bubble's productive nature — constraints and competition are driving exactly the kind of breakthrough innovation needed to make AI economically viable at scale.
Yet, the market correction implies that this was somehow something unexpected. But in fact, this is the exact pattern of behavior that we have witnessed in AI over the past two years.
As we have already begun to see, capital and resource advantages have not created any defensible edge amongst the different AI companies attempting to develop exclusive models. Midjourney is a self-funded team of 11 that is run entirely in Discord. Stable Diffusion is a completely open-sourced text-to-image model that can run on a modest GPU with at least 8 GB of VRAM, such as an iPhone.
Furthermore, SemiAnalysis recently released a leaked internal Google Memo which claimed “We Have No Moat, And Neither Does OpenAI". As the document revealed:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
The pace of innovation occurring within the digitization of the production layer is astonishing, and consequently, new digital manufacturing processes are becoming obsolete almost as soon as they come to market. No one has proven true mastery when it comes to how best to ‘produce’ new AI manufacturing environments.
As the Google Memo confirms, leaner manufacturing processes are scaling better than more intensive ones, as many open source projects are “saving time by training on small, highly curated datasets.”
Since the beginning of March when the Meta’s LLaMA was leaked to the public and open source community got their hands on their first really capable foundation model, things that Google deemed as major opened problems have quickly been resolved, such as:
The memo concludes “Directly Competing With Open Source Is a Losing Proposition” and makes an interesting observation:
Who would pay for a Google product with usage restrictions if there is a free, high quality alternative without them?
This observation recognizes that instead of taking on the sisyphean task of competing with the wave of new leaner, cheaper, faster models that will be spurred on by the open source community, the real prize is to become the distribution interface that delights users, but more importantly, subtly trains and personalizes its own call-and-response distribution mechanism across a network of third-party AI models.
The lessons of history might not repeat, but they rhyme.
II. The Capital Metabolism of AI
Indeed, the AI market demonstrates a distinct pattern in how it processes capital and generates innovation — what we might call its "metabolism." Since May 2023, this cycle has become increasingly apparent, following a predictable sequence:
Initial Surge: Capital and talent flow to AI companies, driven by promising breakthroughs
Infrastructure Investment: Companies channel massive capital expenditure into GPU infrastructure
Model Breakthrough: A new, more capable model emerges, reshaping competitive dynamics
Commercialization Race: Companies (particularly large-scale players) compete to monetize through either consumer applications, developer platforms or both
Optimization Phase: As returns diminish, focus shifts to improving efficiency and reducing costs and competing on a different vector (i.e. test-time compute)
Efficiency Breakthrough: A new, smaller, more efficient model emerges
Market Response: The cycle begins anew, but with more sophisticated applications and capabilities
DeepSeek's breakthrough perfectly illustrates this pattern. As Bill Gurley noted in his conversation with Brad Gerstner on a recent episode of their BG2 podcast, their success may ironically stem from U.S. restrictions on China's GPU access. These constraints forced innovation toward efficiency rather than raw computing power. While many American companies focused on scaling up existing approaches, DeepSeek achieved comparable results through creative optimization of existing models.
The draw down in the financial markets suggests a new skepticism over the pre-DeepSeek consensus regarding CapEx spend and build out. Yet, I think this is the wrong conclusion. Cheaper, more efficient models will percolate through the industry, which will lead to the development of new generative models that can (a) solve problems for more and more markets, (b) automate more and more workflows and (c) be more and more consumer ready.
Said another way, more efficient models won't necessarily reduce overall AI investment; instead, they're likely to expand the market by making AI capabilities accessible to a broader range of applications and users. This economic principle, known as Jevons Paradox, observes that increased efficiency in resource use can lead to increased consumption of that resource. Such a paradox is unfolding in real time: just today (February 5th, 2025), Google announced an increased guidance for $75 billion in capital expenditure this year—a 43% increase from 2024—which blew analysts' consensus projection of $57 billion out of the water.
The real transformation isn't just about making models cheaper — it's about fundamentally changing how we think about AI deployment and, more importantly, unit economics.
III. Traditional Software Economics vs. AI Economics: The LegalZoom Case Study
The beauty of software lies in its marginal cost structure — and thus scalability. Once developed, companies can deliver software services infinitely with a fixed upfront development cost and a near-zero marginal expense per additional user.
This is what makes SaaS businesses among the most lucrative models ever created. They monetize on a marginal, often usage, basis, where customers pay for software to perform a specific job, yet the cost of executing that job is effectively zero. The only real expense is compute, which, thanks to the massive infrastructure buildout during the 1990s dot-com boom and the subsequent rise of cloud computing, is now available on demand at an incredibly low cost.
Because of this dynamic, SaaS businesses enjoy incredible margins on a unit basis. If they can reasonably acquire and retain a customer, these businesses can payback all the costs related to that customer in a matter of months. From that point on, all subsequent servicing of that customer is pure profit.
But AI, as it stands today, has cost structures that are far less innovative; rather it resemble services provided by cheap human labor. Unlike traditional SaaS that has a variable cost of close to zero, AI software incur significant variable costs to service each marginal task. This is often obfuscated from the end consumer, as venture dollars in effect subsidize this dynamic and allow AI applications to operate with subpar (and often) underwater margins.
Indeed, to understand AI unit economics, we first must understand software unit economics. But we must do so on a marginal task level, not a customer level. A task, in this case, is the execution of compute to produce a specific output in service of a specific job. LegalZoom provides an ideal case study, representing a SaaS company in a market highly ripe for AI disruption and which monetizes on a marginal usage basis.
Pulling data from LegalZoom’s most recent 10Q filing, we can see that, as of September 30, 2024, LegalZoom did $679M in trailing twelve-month that quarter, with an ARPU of $264 while servicing 1,717,000 subscription units and generating an impressive 21% EBITDA margin.
Source: LegalZoom 10Q
However, our goal is to determine how much revenue LegalZoom earns on a task usage basis, not on a customer basis, which means we need to estimate the number of tasks LegalZoom runs per year. To do so, we need to break LegalZoom’s revenue down into the specific services they offer, and from there we can make an educated estimate of their task volume. I use Perplexity to help approximate these estimations.
LegalZoom offers annual report filing services starting at $99 plus state filing fees. Assuming an average cost of $150 per annual report (including state fees), and that this service represents about 20% of their revenue, we can estimate:
LegalZoom also offers LLC formation services, which likely represent a significant portion of their business. If we assume 30% of their revenue comes from this service at an average price of $300:
($679 million * 30%) / $300 = 661,700 LLC formations
LegalZoom offers a library of legal forms and document preparation services. They charge $99 per document or $99 per month for a subscription. If we assume 25% of their revenue comes from this service and an average cost of $99 per task:
($679 million * 25%) / $99 = 1,669,192 document preparations
The remaining 25% of their revenue likely comes from various other services such as trademark filings, registered agent services, and compliance packages. If we estimate an average cost of $200 per task:
LegalZoom services approximately 4,147,730 software solutions a year. What does that actually mean on a unit level? How many tasks did LegalZoom’s software execute in service of its solutions?
Tasks can be estimated by analyzing LegalZoom’s cloud configuration. LegalZoom utilizes AWS services such as Amazon EC2 and Amazon EKS for its workloads. These services are scalable, and our estimations are based on LegalZoom’s configuration at its current scale.
Particularly, we measure tasks in terms of total compute and storage usage on a unit basis. We conduct this analysis for each of LegalZoom’s services. Again, I use Perplexity to help approximate these usage estimations.
To estimate LegalZoom's marginal cost per task for servicing its software, we need to analyze its compute and storage usage in terms of:
Usage per vCPU per hour
Usage per 1 GB of storage
Annual Reports
Each annual report requires approximately 5 minutes of processing. Thus:
vCPU hours = (5 Minutes / 60) ≈ 0.0833 vCPU hours
Each annual report requires about 1 MB of storage. Thus:
Storage in GB= 1 MB / 1024 ≈ 0.0009765625 GB
Conducting the same analysis across the four services, we find:
Source: Compounding Thoughts
LegalZoom likely uses 64–128 vCPUs for production workloads. At this workload, AWS EC2 (on-demand) costs~$0.041 per vCPU-hour.
LegalZoom likely requires 100TB of S3 Standard Storage which costs $2,304/month. Thus, their storage costs $0.023 per 1 GB of storage.
Thus, the unit costs equal:
Source: Compounding Thoughts
From here, we can measure the unit economics (on a marginal basis) for LegalZoom to deterministically execute a given task.
Source: Compounding Thoughts
On a blended basis, LegalZoom earns $195 in revenue servicing each marginal task, while paying $0.0039548 to servicing that revenue (on a purely product basis). Pretty remarkable.
But what does this cost structure look like for software that use AI models execute tasks?
Consider, again, the fundamental difference between software (as we historically know it) and AI. Software is a set of instructions that tells a computer how to deterministically perform tasks. AI is a set of instructions that a computer generates itself to inform it how to probabilistically perform tasks.
To execute tasks, many AI software applications use underlying foundational models like GPT-4o. These models charge for individual tokens. Tokens are the smallest unit of data that a language model processes, typically representing a word, part of a word, or even a character, which are used to break down text into manageable pieces for analysis and generation; essentially, they are the building blocks of language processing within an AI system.
To put these numbers in perspective:
1 token is approximately 4 characters in English
1 token is approximately 0.75 words
100 tokens is about 75 words or 1 paragraph
Foundational models charge for two types of inference processing:
Input Inference
Output Inference
Foundational models infer what a specific natural language prompt translates to in terms of tokens. This is the Inference Cost for Prompt, or input inference cost.
Based on these inputs, the model then executes the set of instructions it generates to produce an output in tokens. From there, the model infers what these tokens translate to in natural language (or other multimodal form factor) and delivers the completed task. This is the Inference Cost for Completion, or output inference cost.
We can break down LegalZoom's four main services in terms of input and output tokens required to complete each task. Again, I use Perplexity to help with these estimations.
Annual Report Filing
Input tokens: Approximately 300-400 tokens
This includes the company's financial data, significant changes, and other required reporting information.
Output tokens: Approximately 600-800 tokens
This covers the generated annual report, including formatted financial data and necessary disclosures.
LLC Formation
Input tokens: Approximately 200-300 tokens
This includes the user's input for business details, such as name, structure, and location. The model needs to process this information to understand the requirements.
Output tokens: Approximately 1000-1500 tokens
This covers the generated response, including recommendations for business structure, steps for formation, and initial documentation.
Legal Document Preparation
Input tokens: Approximately 400-600 tokens
This includes specific details required for the legal document, such as names, dates, terms, and conditions.
Output tokens: Approximately 1500-2000 tokens
This covers the generated legal document, including all necessary clauses, terms, and formatting.
Obtaining Licenses and Permits
Input tokens: Approximately 150-250 tokens
This includes the user's business type, location, and specific activities that may require licensing.
Output tokens: Approximately 800-1200 tokens
This covers the list of required licenses and permits, application guidance, and relevant authority information.
Thus, we can underwrite LegalZoom’s new unit cost to service each marginal task using the probabilistic ‘intelligence’ of GPT-4o rather than the deterministic mechanics of legacy software.
Source: Compounding Thoughts
LegalZoom’s product level unit economics would look like this:
Source: Compounding Thoughts
As we can see, LegalZoom’s unit economics drastically worsen with AI intelligence.
The SaaS business model is simply not feasible with GPT-4o.
The DeepSeek Inflection Point
DeepSeek's breakthrough offers hope, reducing costs by 17x compared to GPT-4o.
Source: Pricing Pages, Compounding Thoughts
How does these cost improvements affect the potential for viable AI unit economics?
To understand this, we perform the same analysis for LegalZoom, but using DeepSeek’s foundational model instead of OpenAI’s.
Source: Compounding Thoughts
LegalZoom’s product level unit economics would look like this:
Source: Compounding Thoughts
The blended unit marginal cost for LegalZoom to service a task decreases by 17x with DeepSeek, from $83 to $4.55. Yet, marginal unit cost still needs to decrease by more than 1,165x to be at parity with cloud computing.
Source: Compounding Thoughts
With this step function change in cost, the margin for LegalZoom AI can work.
Source: Compounding Thoughts
LegalZoom improves from a -21% EBITDA margin and losing $141M with GPT-4o to a 19% EBITDA margin and making $128M in EBITDA. Yet, this is still a lower margin and EBITDA income than they earn today.
In sum, DeepSeek's breakthrough offers hope, reducing costs by 17x compared to GPT-4o. Under their pricing:
LegalZoom could maintain a 19% EBITDA margin
Unit economics become viable, though still not matching traditional software margins
The path to further cost reduction becomes clearer
Thus, let’s revisit the two possible futures for AI economics:
The High-Cost Future: AI services remain inherently expensive, ending the era of 99%+ product margin software businesses
The Commoditization Future: AI follows cloud computing's path toward near-zero marginal costs, dominated by an oligopoly of efficient infrastructure providers
All evidence points to a future where cost parity is inevitable. The cost of intelligence will mirror the cost of compute, and one should seriously consider operating under a mental model where the inference cost to service a marginal task is ~$0.00395478. The incentives to achieve such parity are too great, the business models too lucrative, and both the precedent of Moore’s Law in the cloud computing era and scaling improvements over the past two years too prescient.
As models become more efficient, the focus shifts from raw intelligence power (the infra/foundational layer) to distribution, interfaces and user experience (the application layer). This mirrors the evolution of other technological revolutions, where initial expensive, specialized tools eventually become commoditized utilities.
IV. The Path Down the Cost Curve: AI’s Road to Parity with Cloud Computing
The defining function of this AI bubble is not just speculation—it is the rapid acceleration of technological building blocks and infrastructure that will push AI toward cost efficiency. Today, AI services exist in high demand, but the industry has yet to achieve true GDP penetration. The limiting factor? Unit economics.
For AI to become as ubiquitous and transformational as cloud computing, the cost of marginal intelligence must be significantly reduced — becoming not just cheaper, but smarter in how it allocates compute resources.
DeepSeek's recent breakthrough serves as a glimpse into this future. It represents more than just another AI model; it’s a signal that efficiency innovation can drive fundamental cost reductions. DeepSeek achieved three critical advancements:
Comparable performance at a smaller model size – reducing compute overhead.
Lower training and inference costs – making AI applications more affordable to operate.
Optimized resource utilization – increasing the cost efficiency of AI workloads.
Yet, even with these improvements, AI’s cost structure remains fundamentally flawed. A 17x improvement still leaves AI’s marginal costs 1,165x higher than traditional cloud computing. This staggering gap highlights both the challenge and opportunity ahead.
To bridge this divide, AI’s supply-side buildout must surpass short-term demand, triggering a market correction. But this won’t be the end—it will be the start of AI’s true mass adoption. When AI gets cheaper, it gets used more. The expansion is inevitable.
I believe that economic forces will drive AI to reach the same, if not superior, margin profiles as traditional SaaS. The only way to achieve this is for the cost of probabilistic intelligence to approach the cost of deterministic compute—meaning near-zero variable costs, just like in software.
V. The Future of AI Business Models and Interfaces
The companies that succeed in AI’s next chapter will be those that master the balance between deterministic software execution and probabilistic AI-driven intelligence. They must architect systems that seamlessly offload tasks to the most cost-efficient compute environments, preserving the best of both worlds—the reliability of traditional software with the adaptability of AI.
But the real transformation AI promises isn’t just about making existing processes more efficient—it’s about replacing entire workflows, and in many cases, the labor behind them. This level of economic disruption is almost impossible to quantify. A 1,000,000x productivity leap is coming, as AI will handle a near-infinite range of tasks, adapting to nuances and complexities in ways no previous technology could.
Yet, that also means that the number of individual tasks that a software will execute for a given customer, or it’s variable seat cost, is going to scale nonlinearly as well. More total usage will demandan equal and exponential decrease in unit cost of intelligence. Exponential decrease in unit cost of intelligence will lead to more total demand. Jevon’s paradox begets a virtuous cycle.
As with cloud computing, as the variable unit cost of an individual software task approached zero, the ability for software to solve problems and take on more tasks increased nonlinearly. Meaning, while the revenue per token will surely decrease, which will also surely lead to pricing pressure on GPUs and the revenue Nvidia earns on each GPU will likely decrease, the total size of this market will explode as demand reverberates throughout the supply chain.
One would think raw compute is more of a commodity than raw intelligence. The processing power to execute deterministic tasks is quite fungible. The same raw compute can be exchanged to power pretty much any specific binary software process.
On the other hand, the processing power to generate instructions to probabilistically execute tasks is much less fungible and much more open-ended. It requires reasoning and inference, both of which tend to be more effective in specifically trained datasets and context windows. Yet, this perhaps reveals where commoditization will occur: intelligence may not be commoditized, but the components of intelligence (reasoning, inference, memory) will be.
In fact, intelligence may be the function of software and the ‘app layer’ — which is essentially what it always has been — but software intelligence as we have known it will, in hindsight, appear to be more akin to a Mechanical Turk.
From Railroads to Automobiles: AI’s Evolution Beyond Software
History provides a revealing parallel. The deterministic computing era (1990s–2025) will, in hindsight, resemble the railroad boom of the Industrial Age—a transformative breakthrough that reshaped industries but remained bound by fixed, predetermined pathways. Railroads revolutionized movement but were constrained by the rigid infrastructure of their tracks, just as traditional software has been confined by deterministic logic and predefined workflows.
AI, by contrast, is more akin to the automobile—a probabilistic, agentic system that expands the possibilities of movement, not by adhering to fixed routes, but by dynamically navigating an open-ended world. Just as automobiles unlocked untapped economic potential, enabling greater autonomy and accessibility, AI will break free from the rigid structures of deterministic software, ushering in an era where intelligence can adapt, learn, and self-direct.
Railroads still serve a vital function, just as deterministic software will continue to underpin digital infrastructure. But the automobile vastly expanded the market for transportation, transforming how people work, travel, and interact with the world. AI will do the same for intelligence—unleashing new capabilities, reshaping entire industries, and redefining how humans work, create, and live.
VI. Implications and Conclusions: The Next Era of Computing
The future of AI is not just about better models or lower costs—it’s about reinventing how humans interact with machines. Unlike traditional software, which follows predefined instructions, AI can generate its own instructions to solve a task—meaning the interface layer will define everything.
For the past two decades, software innovation has focused on reducing friction in human-computer interactions. From graphical interfaces to touchscreens to mobile apps, the breakthroughs that shaped the internet economy were ultimately about making technology more intuitive. AI represents the next great leap—a shift from deterministic software to probabilistic intelligence that understands, reasons, and adapts.
The current chat-based AI interface paradigm is a transitional phase, much like the command-line interfaces of early computing. While powerful, text-based models require too much effort from users—they demand precise prompts, iterative refinements, and cognitive load that limits accessibility. This is neither scalable nor the natural end state.
The real unlock will be multimodal, high-bandwidth interfaces that optimize for how humans actually communicate. Consider the vast difference in information transfer rates:
The human eye ingests data at 100 megabits per second.
Spoken language transmits information at just 39 bits per second.
Text-based chat interfaces are even slower.
To fully harness AI’s potential, interfaces must compress, contextualize, and automate interactions in ways that minimize cognitive friction. The future belongs to AI-native interfaces that rethink how intelligence is delivered—not just responding to prompts but anticipating intent, learning from patterns, and structuring knowledge into easily digestible formats.
The evolution of human communication has always been about compression. As Chris Paik has brilliantly observed, stories, songs, and myths are cognitive compression algorithms—ways to encode and transmit vast amounts of meaning efficiently. A single parable can encapsulate an entire worldview, just as a melody can evoke deeply embedded cultural knowledge. These formats endure because they optimize cognitive bandwidth, allowing complex ideas to be shared with minimal effort.
AI lacks this efficiency today. Current interfaces force users to manually craft prompts and sift through responses, creating a bottleneck between human intention and machine execution. The future of AI interaction will depend on developing new compression formats that remove friction from human-computer interaction.
Much like how Google’s search box, Facebook’s News Feed, and Amazon’s recommendation engine became the defining interfaces of the web era, the AI-native interface that seamlessly integrates intelligence into daily workflows will determine the winners of this era. Indeed, modern SaaS companies have succeeded not by owning differentiated computation resources, but by perfecting interface design—wrapping structured tasks in intuitive user experiences that lower friction, increase engagement, and drive network effects. The AI era will follow the same trajectory. The companies that win will not necessarily be those with the best models but those that own distribution—the seamless, habitual relationship with demand.
This follows a clear pattern from Aggregation Theory:
The best distributors own demand, not supply.
Interfaces will dictate who wins the AI era—not the models themselves.
In sum, the AI revolution isn’t just about intelligence—it’s about how that intelligence is accessed and experienced. The companies that win won’t just build better models; they will build better ways to think with AI. Just as graphical interfaces replaced command-line inputs, the AI-native paradigm will make today’s prompt engineering feel like an archaic relic.
Thanks for reading Compounding Thoughts! Subscribe for free to receive new posts and support my work.